NVIDIA AI Releases Canary-Qwen-2.5B: A State-of-the-Art ASR-LLM Hybrid Model with SoTA Performance on OpenASR Leaderboard
NVIDIA has just released Canary-Qwen-2.5B, a groundbreaking automatic speech recognition (ASR) and language model (LLM) hybrid, which now tops the Hugging Face OpenASR leaderboard with a record-setting Word Error Rate (WER) of 5.63%. Licensed under CC-BY, this model is both commercially permissive and open-source, pushing forward enterprise-ready speech AI without usage restrictions. This release marks a significant technical milestone by unifying transcription and language understanding into a single model architecture, enabling downstream tasks like summarization and question answering directly from audio.
Key Highlights
5.63% WER – lowest on Hugging Face OpenASR leaderboard
RTFx of 418 – high inference speed on 2.5B parameters
Supports both ASR and LLM modes – enabling transcribe-then-analyze workflows

Commercial license (CC-BY) – ready for enterprise deployment
Open-source via NeMo – customizable and extensible for research and production

Model Architecture: Bridging ASR and LLM
The core innovation behind Canary-Qwen-2.5B lies in its hybrid architecture. Unlike traditional ASR pipelines that treat transcription and post-processing (summarization, Q&A) as separate stages, this model unifies both capabilities through:

FastConformer encoder: A high-speed speech encoder specialized for low-latency and high-accuracy transcription.
Qwen3-1.7B LLM decoder: An unmodified pretrained large language model (LLM) that receives audio-transcribed tokens via adapters.
The use of adapters ensures modularity, allowing the Canary encoder to be detached and Qwen3-1.7B to operate as a standalone LLM for text-based tasks. This architectural decision promotes multi-modal flexibility — a single deployment can handle both spoken and written inputs for downstream language tasks.
Performance Benchmarks
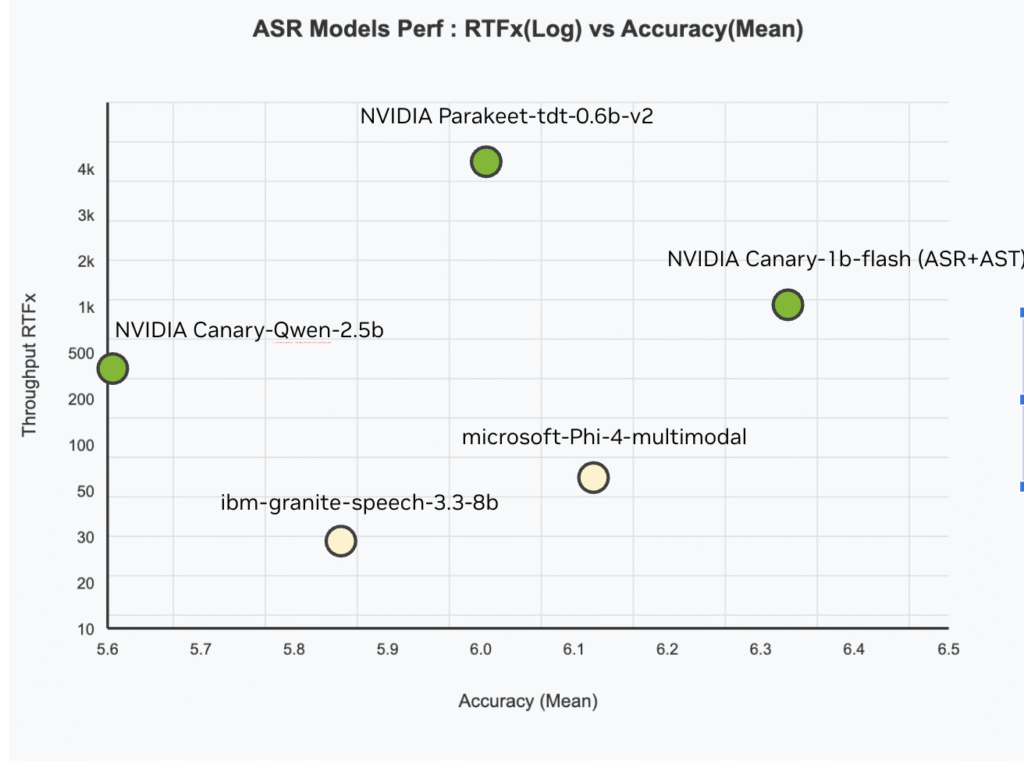
Canary-Qwen-2.5B achieves a record WER of 5.63%, outperforming all prior entries on Hugging Face’s OpenASR leaderboard. This is particularly notable given its relatively modest size of 2.5 billion parameters, compared to some larger models with inferior performance.
The 418 RTFx (Real-Time Factor) indicates that the model can process input audio 418× faster than real-time, a critical feature for real-world deployments where latency is a bottleneck (e.g., transcription at scale or live captioning systems).

Dataset and Training Regime
The model was trained on an extensive dataset comprising 234,000 hours of diverse English-language speech, far exceeding the scale of prior NeMo models. This dataset includes a wide range of accents, domains, and speaking styles, enabling superior generalization across noisy, conversational, and domain-specific audio.
Training was conducted using NVIDIA’s NeMo framework, with open-source recipes available for community adaptation. The integration of adapters allows for flexible experimentation — researchers can substitute different encoders or LLM decoders without retraining entire stacks.
Deployment and Hardware Compatibility
Canary-Qwen-2.5B is optimized for a wide range of NVIDIA GPUs:
Data Center: A100, H100, and newer Hopper/Blackwell-class GPUs
Workstation: RTX PRO 6000 (Blackwell), RTX A6000
Consumer: GeForce RTX 5090 and below
The model is designed to scale across hardware classes, making it suitable for both cloud inference and on-prem edge workloads.
Use Cases and Enterprise Readiness
Unlike many research models constrained by non-commercial licenses, Canary-Qwen-2.5B is released under a CC-BY license, enabling:
Enterprise transcription services
Audio-based knowledge extraction
Real-time meeting summarization
Voice-commanded AI agents
Regulatory-compliant documentation (healthcare, legal, finance)
The model’s LLM-aware decoding also introduces improvements in punctuation, capitalization, and contextual accuracy, which are often weak spots in ASR outputs. This is especially valuable for sectors like healthcare or legal where misinterpretation can have costly implications.
Open: A Recipe for Speech-Language Fusion
By open-sourcing the model and its training recipe, the NVIDIA research team aims to catalyze community-driven advances in speech AI. Developers can mix and match other NeMo-compatible encoders and LLMs, creating task-specific hybrids for new domains or languages.
The release also sets a precedent for LLM-centric ASR, where LLMs are not post-processors but integrated agents in the speech-to-text pipeline. This approach reflects a broader trend toward agentic models — systems capable of full comprehension and decision-making based on real-world multimodal inputs.
Conclusion
NVIDIA’s Canary-Qwen-2.5B is more than an ASR model — it’s a blueprint for integrating speech understanding with general-purpose language models. With SoTA performance, commercial usability, and open innovation pathways, this release is poised to become a foundational tool for enterprises, developers, and researchers aiming to unlock the next generation of voice-first AI applications.
Check out the Leaderboard, Model on Hugging Face and Try it here. All credit for this research goes to the researchers of this project.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.